-
상관관계 분석 (Correlation Analysis)BIG DATA & AI/Mathematics 2021. 11. 22. 21:09반응형
두 feature의 상관관계를 분석하고 싶을 때 사용되는 기법들을 소개하려고 한다. 가령 gender에 따라 fiction과 non-fiction 장르의 선호도를 알기 위해서는 우선 두 feature가 상관관계가 있나? 있다면 얼마나 있는지? 이런 물음들이 필요하다.
Nominal data - labeled, named 즉 discrete하고 multi-value로 이름 붙여진 데이터를 의미한다 - 의 경우 카이제곱 검정 (Chi-Square Test)을 많이 사용한다.

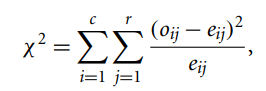
카이제곱=(측정값-기대값)제곱을 기대값으로 나눈 값 
위의 예제를 풀면 correlation 값은 이러하다. 또한 correlation 개념 관해서 중요한 점은 결코 Correlation does not imply causality 이다. 상관관계와 인과관계는 같지 않다는 뜻인데, 예를 들어 hospital의 개수와 car-theft의 사건 수는 correlated 하다고 말할 수 있지만 causally는 아니다. 병원 수가 많아서 교통 사고가 많아진 원인도 아니고, 교통 사고가 많아서 병원 수가 많아졌다는 것도 성립하지 않는다. 사실 그 둘 사이에는 population이라는 third variable이 있었고, 이에 correlated하다고 정의내릴 수 있다.
Numeric data의 경우에는 Correlation Coefficient 즉 Pearson's product moment coefficient (피어슨 상관 계수)를 주로 사용한다. 피어슨 상관 계수는 코시-슈바르츠 부등식에 의해 +1과 -1 사이의 값을 가지며, +1은 완벽한 양의 선형 상관 관계, 0은 선형 상관 관계 없음, -1은 완벽한 음의 선형 상관 관계를 의미한다.
또한 Covariance (공분산) 라는 개념도 있는데, correlation과 비슷하며 두 변수의 상호의존성이 강하다는 것을 보여준다. 만약 2개의 변수중 하나의 값이 상승하는 경향을 보일 때 다른 값도 상승하는 선형 상관성이 있다면 양수의 공분산을 가진다. 반대로 2개의 변수중 하나의 값이 상승하는 경향을 보일 때 다른 값이 하강하는 선형 상관성을 보인다면 공분산의 값은 음수가 된다.

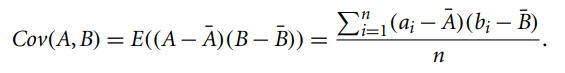

AllElectronics와 HighTech는 양의 공분산을 가진다. Reference
Data Mining. Concepts and Techniques, 3rd Edition (The Morgan Kaufmann Series in Data Management Systems)
반응형'BIG DATA & AI > Mathematics' 카테고리의 다른 글
유튜브 기초 수학 : 3Blue1Brown의 Essence of linear algebra 수강 후기 (0) 2021.08.03